Laser Tagger는 문장을 생성하는 과정에 대해서 다른 관점을 제시한 논문 Encode, Tag, Realize: High-Precision Text Editing을 구현한 오픈소스 분석기입니다.
0. 요약
레이저 태거는 시퀀스 태깅 모델입니다.
문서의 생성 자체를 문서의 편집이라 가정하고 입력으로 들어온 문서에 대해서 어떤 '편집 작업'을 할지 예측합니다.
예측을 위해서 기존에 없었던 모델을 만들어 제안하며, 영어 문서에 대해서 평가를 진행합니다.
LaserTagger는 3가지 NLP Task 에서 SOTA 성능을 보였습니다.
1. 문장 합성
2. 문장 분절
3. 추상 요약(특히나 놀라운 부분입니다. 일반적인 문서 요약은 추출 요약이 대부분이기에 더더욱 그렇습니다.)
또한 실질적인 추론 시간역시 기존의 모델에 비해서 매우 짧아 실제 환경에서 구동하기에도 좋아 보입니다.
1. 서론
seq2seq 는 여러 작업에서 좋은 성능을 보여 왔으나, 문장 분절, 문장 합성등에 있어 입력값을 출력값이 그대로 덮어 쓰는 경향을 보입니다.
이러한 현상(= copy mechanism)은 수학적으로나 직관적으로나 전혀 쓸모가 없는 결과라는 것을 바로 알 수 있습니다.
copy mechnism으로는 사전 밖 단어에는 대응하지 못하며, 특히나 데이터가 적을 때 이 단점이 더더욱 두드러집니다.
이러한 현상을 해결하기 위해서 당 논문에서는 다음과 같은 편집 작업을 학습시키는 것을 제안합니다.
- KEEP
- DELETE
- ADD
- SWAP
- PRONOMINALIZE
이 작업들은 입력 데이터(source)에 대해서 출력되어야할 옳바른 출력 데이터(target)만 있다면
다항식 시간 안에 수행되는 알고리즘을 통해 간단하게 산출됩니다.
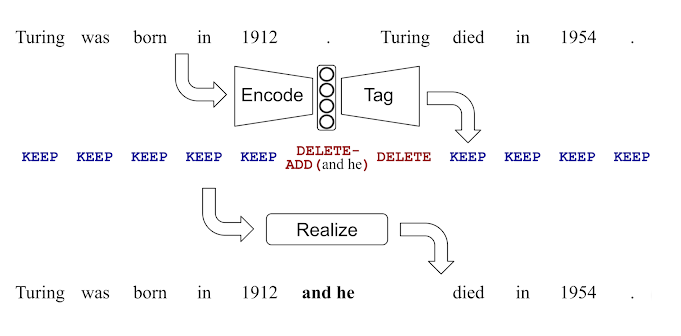
Laser Tagger는 3단계의 작업 흐름으로 구성됩니다.
- Encode : source의 요약 정보 표현(Embedding)을 구성.
- Tag : AI 모델을 통해서 태그를 할당.
- Realize : 할당된 태그를 토대로 실제 문장을 구성.
위 3단계 작업에서 학습이 필요한 부분은 오직 Tag 부분 뿐입니다.
Encode는 기존 학습된 BERT 모델을 사용하였으며, Realize는 규칙 기반입니다.
아래 그림은 해당 작업을 간단하게 나타낸 것입니다.
해당 논문이 구현을 통해서 기여하고자 하는 바는 아래와 같습니다.
- 생성 작업을 편집 작업으로 볼 수 있다는 insight 제공
- LaserTagger 구현체의 오픈소스 제공
- BERT 보다 성능 좋은 모델의 제공 (정확도, 속도, 데이터 요구량)
2. 이전 연구
- 문서 단순화 : 난잡한 문서의 구조를 변경하여 의미와 내용은 유지하되 가독성을 향상시키는 것이 그 목적입니다.
- 단일 문서 요약 : 단순히 문서를 요약하는 작업입니다. 토큰 단위의 삭제(추상)와 문장 단위의 삭제(추출)를 기반으로 하는 2가지 모델이 있습니다.
- 문법 오류 교정 : 문법 오류를 분류화 하려는 접근이 주를 이루었습니다.
3. 태깅 문제로서의 편집
논문의 골자는 문서의 편집을 태깅으로 변환 하는 것에 있습니다.
서론에서 밝혔듯, 이 방법으로 실제 문장을 생성하는 과정은 3단계입니다.
하나하나 천천히 살펴봅니다.
3.1 편집 작업들
모든 토큰에는 태그가 하나하나 할당이 됩니다. 할당이 되는 태그는 2가지이며, 여기에 추가로 다른 태그가 붙을 수 있습니다.
(1) Base Tag : KEEP 과 DELETE 2종류로 구성된 태그. 모든 토큰에 반드시 포함됩니다.
(2) added phrase Tag : 출력에 포함되는 '구' 를 삽입하기 위한 태그입니다. 이 태그는 존재할 수도, 존재하지 않을 수도 있습니다.
해당 태그는 어떠한 '구'를 삽입해야하는 지에 대한 index를 포함합니다!
☆ Laser Tagger에서 토큰의 단위는 단어가 아닌 '구(句)' 입니다. 한국어 NLP에서 주로 토큰을 형태소로 구성하는 것과는 다릅니다.
구 단위를 사용하였기에 결과에 오차가 있더라도, 실제 문장과 비슷한 형식으로 출력이 나옵니다.
(3) 바로 위의 2개 태그를 결합합니다. 그래서 각각의 '구' 사전에 매칭되어 굉장히 유니크한 태그가 생성됩니다.
(4) 커스텀 태그로써 SWAP 태그, PRONOMINALIZE 태그 2종류가 있습니다.
SWAP 태그는 문장의 합성등, 2개 이상의 문장을 입력으로 받을 때 사용합니다.
태그들을 다시 문장으로 바꿀 때, 가장 먼저 적용되며, 토큰들의 위치를 바꾸는데에 사용합니다.
PRONIMINALIZE 태그는 사용자 사전 기능에 해당합니다.
이 태그는 모델이 예측 대상으로 삼지 않으며, 사용자가 직접 정의하고 사용하는 태그입니다.
3.2 '구' 사전의 최적화
Laser Tagger는 특화된 '구'사전을 갖습니다. Laser Tagger의 Endoder를 담당하는 BERT는 자신만의 단어사전을 따로 갖습니다.
'구' 사전은 added phrase 태그의 예측 값, 입력 데이터의 전처리 과정, 기본적인 속도 향상 등에 사용됩니다.
구 사전을 만드는 문제는 다음과 같이 표현할 수 있습니다.
'구'들의 집합인 A_i 들 중에서 최대 사이즈가 L 인 사전 A_i를 선택하는 문제.
수식을 많이 줄여놨습니다만, 해당 문제는 NP_hardness 이기 때문에 쉽게 풀리지 않는다는 것이 논문의 골자입니다.
사전을 만드는 방법은 다음과 같습니다.
(1) 훈련데이터들로부터 가져온 source, target을 정렬합니다.
(2) 정렬한 두 문장에서 LCS(최장 공통 부분 수열)을 찾습니다.
(3) LCS를 구성하는 요소가 아닌 것들을 모두 구 사전에 밀어넣습니다. 이미 있다면 빈도수를 +1 해줍니다.
(4) 사전에 들어간 구 들을 빈도수에 따라 정렬하고 최대 사이즈에 맞게 잘라냅니다.
3.3 Target을 Tag로 변환
일단 사전이 만들어 졌다면, 이제 target을 tag 시퀀스로 변환할 수 있습니다.
사전에 없는 '구'는 그냥 drop되고, 모델 학습시 add phrase Tag가 들어오게 학습 될 것입니다.
이런 과정을 통해서 더 일반화되고 나은 모델이 완성됩니다.
예를 들어 ';' 라는 구가 들어왔다면, 해당 구를 아예 생성하지 않고 ',' 라는 구를 제시하여 더 나은 모델을 만드는 과정입니다.
해당 파트는 논문에서도 말로 설명하지 않고 알고리즘을 의사 코드로 제시하였습니다.
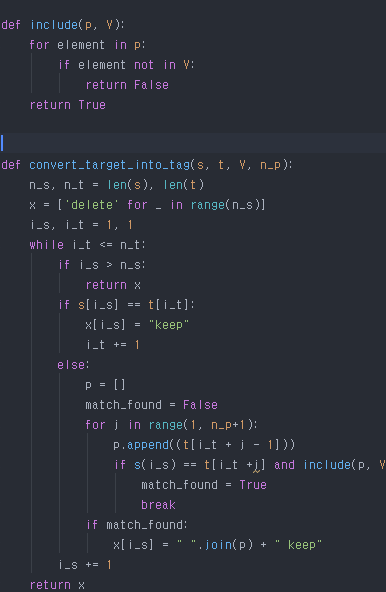
의사코드를 구현하면 위와 같습니다.
3.4 Realization
위의 과정대로 타겟 텍스트를 태그로 변환했다면, 변환된 태그를 다시 텍스트로 바꾸는 작업도 필요합니다.
기본적으로 앞에서부터 차례대로 태그의 내용대로 입력 문장을 수정합니다.
커스텀 태그들의 경우에는 그보다 앞서 가장 먼저 처리하여, SWAP,PRONOMINALIZE 의 본연의 기능을 살리도록 합니다.
4. 학습 모델의 구조.
Laser Tagger에서 학습이 필요한 부분은 Tag 작업입니다.
Tag작업은 크게 2개 부분으로 나뉘며, Encoder와 Decoder의 구조입니다.
Endocer : BERT Transformer를 그대로 차용하여 사용했습니다.
12층의 self attention Layer를 사용한 구조인데, 이 논문이 쓰여진 2019년 9월 기준으로 가장 성능이 좋습니다.
논문에서는 그냥 선수학습된 BERT를 그대로 가져다 붙였다 합니다.
Decoder : BERT의 원본에서는 sequence tagging을 위해 아주 간단한 decoder구조를 사용했지만, 해당 구조에는 문제가 있습니다.
일단 예측 자체가 독립적이 되어서 이전 예측된 Tag들이 다음 예측될 Tag에 영향을 주지 못합니다.
이 문제점을 해결하기 위해 자기회귀 모델이 제안되어 있으며, 이는 구조적으로 펼쳐진 RNN과 흡사합니다.
5. 실험 및 검증
이 부분은 시행한 자연어 처리 과제와 그 결과만을 간략하게 기술하겠습니다.
(SARI score : n-gram('구')들의 add, keep, delete에 대한 F1 점수의 평균. 간략화 모델에 자주 사용되는 평가법입니다.)
- 문장 합성 : Exact -53.8, SARI-85.5
- 문장 분절 : Exact - 15.2, SARI-61.7
- 추상 요약 : Exact : 3.8, SARI- 44.8
- 문법 교정 : F_0.5(검정력) : 40.52
6. 결론 및 한계.
여러가지 측면에서 seq2seq 보다 나은점을 보여주었지만 아직 해결 못한 부분이 있습니다.
- 임의의 단어들에 대해서 '재배열' 하는 태스크는 현재의 접근방식으로는 해결하기 힘듭니다.
- 영어에 비해서 형태론적으로 풍부한 언어에는 적용하기 힘들지도 모릅니다.
해당 논문의 내용이 한국어로 정리된 블로그:
2020년 1월 31일(금) 구글 AI 리서치 블로그 | Sequence-to-Sequence(seq2 seq) 모델들은 기계 번역 분야에 혁명을 가져왔으며,...
brunch.co.kr
'NLP' 카테고리의 다른 글
| google ads 관련 논문 (0) | 2021.05.05 |
|---|---|
| Attention is all you need 리뷰 (0) | 2021.04.05 |
